![]()



Risk prediction models for lung cancer: Perspectives and dissemination
(Tang et al., 2019)
Abstract
Objective: The objective was to systematically assess lung cancer risk prediction models by critical evaluation of methodology, transparency and validation in order to provide a direction for future model development.
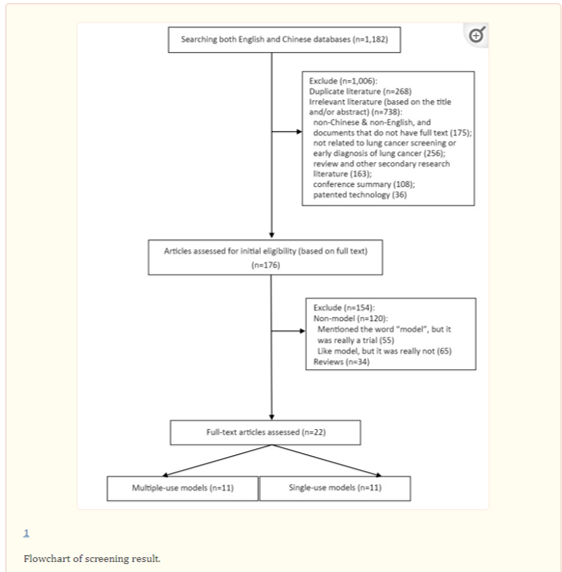
Methods: Electronic searches (including PubMed, EMbase, the Cochrane Library, Web of Science, the China National Knowledge Infrastructure, Wanfang, the Chinese BioMedical Literature Database, and other official cancer websites) were completed with English and Chinese databases until April 30th, 2018. Main reported sources were input data, assumptions and sensitivity analysis. Model validation was based on statements in the publications regarding internal validation, external validation and/or cross-validation.
Results: Twenty-two studies (containing 11 multiple-use and 11 single-use models) were included. Original models were developed between 2003 and 2016. Most of these were from the United States. Multivariate logistic regression was widely used to identify a model. The minimum area under the curve for each model was 0.57 and the largest was 0.87. The smallest C statistic was 0.59 and the largest 0.85. Six studies were validated by external validation and three were cross-validated. In total, 2 models had a high risk of bias, 6 models reported the most used variables were age and smoking duration, and 5 models included family history of lung cancer.
Conclusions: The prediction accuracy of the models was high overall, indicating that it is feasible to use models for high-risk population prediction. However, the process of model development and reporting is not optimal with a high risk of bias. This risk affects prediction accuracy, influencing the promotion and further development of the model. In view of this, model developers need to be more attentive to bias risk control and validity verification in the development of models.
Español
Modelos de predicción de riesgo de cáncer de pulmón: Perspectivas y diseminación
Resumen
Objetivo: El objetivo fue valorar de manera sistemática los modelos de predicción de riesgo de cáncer de pulmón mediante una evaluación crítica de la metodología, transparencia y validación para proveer dirección para el futuro desarrollo de modelos.
Métodos: Se completaron búsquedas electrónicas en bases de datos en inglés y chino (incluyendo PubMed, EMbase, la biblioteca Cochrane, Web of Science, la Infraestructura Nacional de Conocimientos de China, Wanfang, la Base de Datos de Literatura China BioMedical y otros sitios web oficiales de cáncer) hasta el 30 de abril de 2018. Las principales fuentes reportadas fueron datos de entrada, suposiciones y análisis de sensibilidad. La validación del modelo se basó en lo descrito en las publicaciones sobre validación interna, validación externa y/o validación cruzada.
Resultados: Se incluyeron 22 estudios (que contenían 11 modelos de usos múltiples y 11 de uso único. Los modelos originales se desarrollaron entre 2003 y 2016. La mayoría de ellos eran de los Estados Unidos. Se usó la regresión logística multivariada para identificar los modelos. El área bajo la curva mínima en los modelos fue 0.57, y la mayor fue 0.87. La estadística C menor fue 0.59, y la mayor, 0.85. Se validaron 6 estudios con validación externa y 3 con validación cruzada. En total, 2 modelos tenían alto riesgo de sesgo, 6 modelos reportaron que las variables más usadas eran edad y duración del tabaquismo y 5 modelos incluyeron historia familiar de cáncer de pulmón.
Conclusiones: La precisión de la predicción de los modelos fue en general alta, lo cual indica que es factible usar los modelos para predecir poblaciones de alto riesgo. Sin embargo, el proceso del desarrollo y reporte de los modelos no es óptimo, con un alto riesgo de sesgo. Este riesgo afecta la precisión de la predicción, influenciando la promoción y desarrollo adicional del modelo. En vista de esto, los desarrolladores de modelos deben prestar más atención al control de riesgo de sesgo y la verificación de la validez en el desarrollo de modelos.